

Agent-First
Full CLI that mirrors every UI action. Built-in skill gives your agent eval-specific guidance.
Local Dashboard
Compare runs, annotate, and export from a local web UI.
Flexible
Quick smoke tests or deep multi-model comparisons. Pytest-style assertions, clean code.
Local-Only
Code, data, and results live in your repo. No external platforms or auth.
Get Started
Install the EZVals skill for your coding agent: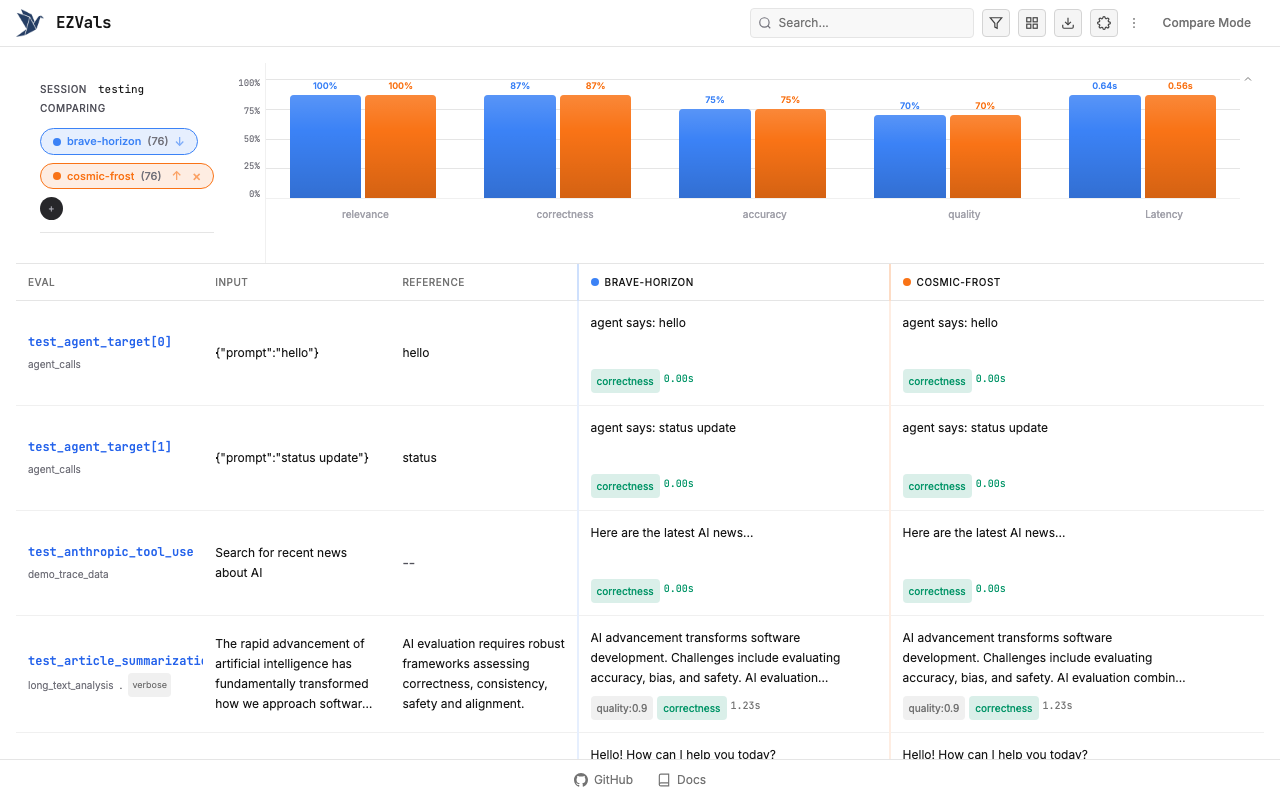
Setup Details
Install the library directly, configure your project, and learn how EZVals works under the hood.